




こんにちは。YUKINOSUKEです。
最近、仕事の合間にコードを書いていると、ふと思うことがあります。「このPythonの技術、競馬にそのまま応用したらすごいことになるんじゃないか?」と。きっと、このページにたどり着いたあなたも、同じようなワクワクを感じているのではないでしょうか。プログラミングのスキルを活かして、データに基づいた自分だけの予想ロジックを組み上げる。そしてあわよくば、回収率100%の壁を超えてみたい。そんなエンジニア心をくすぐるテーマですよね。でも、いざ始めようとすると、データの取得方法や法律的なリスク、どのアルゴリズムを使えばいいのかなど、疑問が山積みで手が止まってしまうことも多いはずです。この記事では、私が実際に試行錯誤しながら学んだ、安全かつ実践的な開発フローを余すところなくシェアします。
- GitHubや書籍を活用した効率的な学習と開発のスタート方法
- スクレイピングのリスクを回避し公式データを扱う重要性
- LightGBMやTarget Encodingを用いた本格的なモデル構築
- 血統データのグラフ化など回収率を上げるための高度な戦略
競馬予想AIをPythonで自作するための基礎手順
まずは、いきなり複雑なコードを書き始めるのではなく、開発の全体像を掴むところから始めましょう。Pythonという強力な武器を使って、どのように競馬予測という課題にアプローチするのか。ここでは、環境構築から基本的なモデルの作成、そして避けて通れないデータの取り扱いについて、初心者が最初の一歩を踏み出すためのロードマップを解説します。
GitHubのソースコードを活用して開発を始める
ゼロから全てのコードを自分一人で書き上げるのは、確かに素晴らしい学習機会ですが、同時にそれが「最大の挫折原因」になってしまうことも珍しくありません。特に競馬予想AIというジャンルは、学習モデルを作る前の段階――つまり、過去データの整形や紐付け、欠損値の処理といった「前処理」だけで、全工程の8割以上の時間を費やす泥臭い作業が必要になるからです。
-

- YUKINOSUKE
私がこれから開発を始める方に強くおすすめしているのが、GitHub上で公開されている優れたオープンソースプロジェクト(OSS)を徹底的に「模倣」し、分析することです。先人たちが数百時間をかけて構築した設計思想を、わずか数分で自分の手元に再現できる。これこそが、現代のエンジニアに許された最大の特権だからです。
宝の山を見つける検索キーワードと見るべきリポジトリ
GitHubの検索窓に「horse racing prediction python」や「競馬予想 ai」と入力してみてください。世界中の開発者が公開したリポジトリがずらりと並びます。しかし、玉石混交であることも事実です。
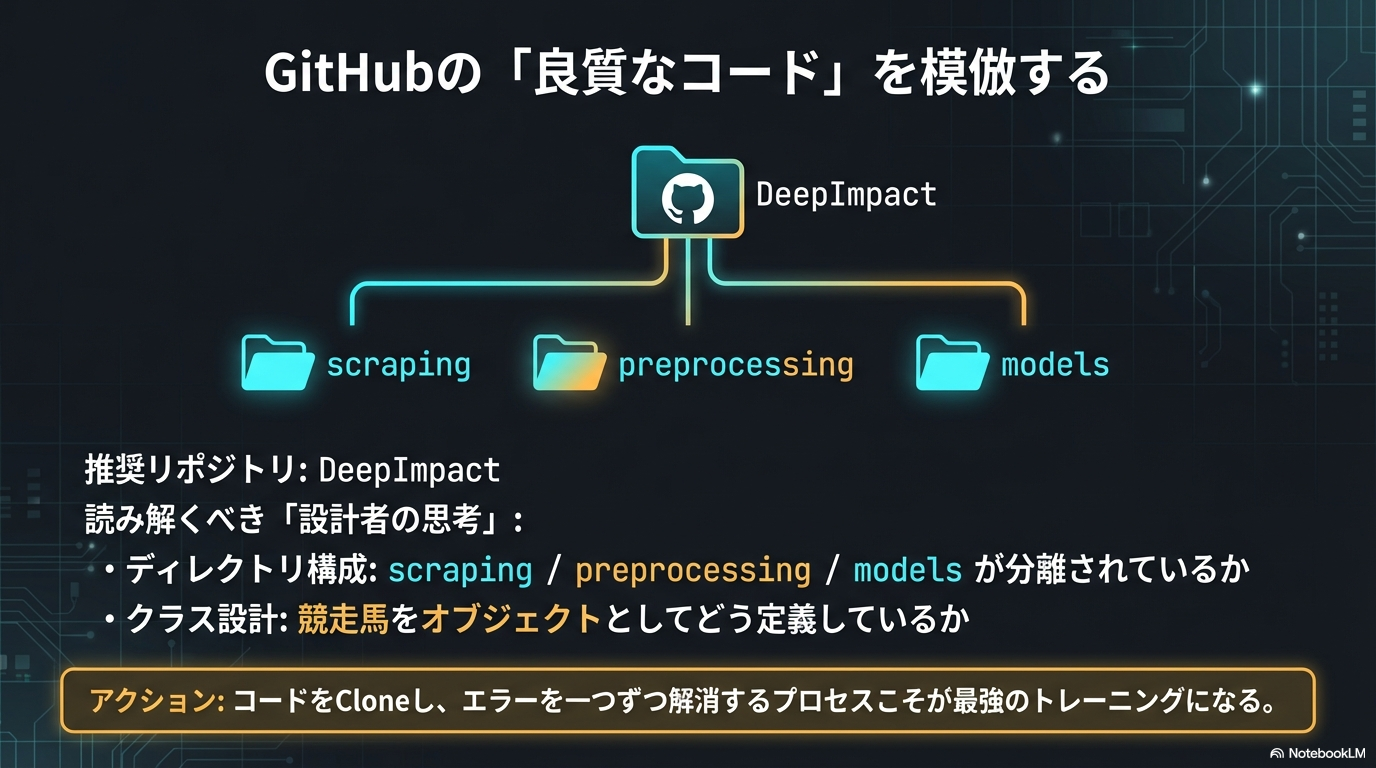
私が特に参考になると感じたリポジトリの一つに、日本の開発者が公開している「DeepImpact」があります。このプロジェクトは、単に予測するだけでなく、LambdaRankを用いたランキング学習を実装しており、ディレクトリ構成やクラス設計が非常に洗練されています。こうした「質の高いコード」を読むことは、参考書を10冊読むよりも深い学びを与えてくれます。
-
- YUKINOSUKE
ソースコードから読み解くべき「開発者の思考」
他人のコードを見る際、漫然と眺めるのではなく、以下のポイントに注目して「なぜ作者はこう書いたのか?」を推測しながら読むのがコツです。
| 注目ポイント | 読み解くべき内容と意図 |
|---|---|
| ディレクトリ構成 | 「scraping(収集)」「preprocessing(加工)」「models(学習)」が明確に分かれているか?美しい構成は、データの流れ(パイプライン)が整理されている証拠です。 |
| クラス設計 | 競走馬を「Horseオブジェクト」として定義しているか? レース結果をどのように保持しているか? オブジェクト指向設計のお手本になります。 |
| 依存ライブラリ | requirements.txtを見ることで、そのAIがどのバージョンのPandasやLightGBMに依存しているかが一目でわかります。バージョンの違いによるエラー(Dependency Hell)を避けるための重要な手がかりです。 |
| 特徴量の作り方 | ここが最大の「宝」です。「騎手の連対率をどう計算しているか」「前走との間隔をどう数値化しているか」など、 作者独自の工夫がコードの随所に隠されています。 |
実際に動かすことが最大の学習
見るだけでは不十分です。実際にターミナルを開き、git cloneコマンドでリポジトリを自分のパソコンに取り込み、動かしてみましょう。
正直に言えば、公開されているコードが一発でエラーなく動くことは稀です。ライブラリのバージョンが古かったり、データの保存場所が違ったりして、必ずと言っていいほどエラー画面(Traceback)に遭遇します。しかし、「このエラーを一つひとつ検索して解消していくプロセス」こそが、最強のトレーニングになります。
エラー解決のサイクル
- 「ModuleNotFoundError」が出たら、
pip installで不足しているライブラリを入れる。 - 「FileNotFoundError」が出たら、コード内のパス指定(相対パス/絶対パス)を読み解き、適切な位置にフォルダを作る。
- 「DataFrame shape mismatch」が出たら、前処理の段階でデータの列数が合っていない可能性を疑う。
こうしてエラーと格闘するうちに、Pythonの環境構築力やデバッグ能力が飛躍的に向上します。そして、ようやくコードが完走し、自分の手元でAIが予想を弾き出した時の感動はひとしおです。まずは「巨人の肩に乗る」つもりで、既存のコードを動かすところから始めてみてください。
機械学習のモデル構築に必要なライブラリ解説
Pythonが競馬予想AI開発におけるデファクトスタンダード(事実上の標準)としての地位を確立している最大の理由は、データサイエンスと機械学習に特化したライブラリのエコシステムが、他の言語と比較して圧倒的に充実しているからです。JavaやC#でも開発は可能ですが、データ分析の試行錯誤(トライ&エラー)のスピードにおいて、Pythonの右に出るものはありません。
私が普段の開発プロセスで「これだけは絶対に外せない」と確信している主要なライブラリスタックについて、単なる機能説明だけでなく、競馬予想という文脈でどのように活用されるのか、その核心を詳しく解説します。
-

- YUKINOSUKE
| ライブラリ名 | 具体的な役割と競馬AIにおける重要性 |
|---|---|
| Pandas | データの「まな板」であり、開発時間の8割を共に過ごす相棒です。CSVの読み込みはもちろん、以下のような複雑な処理を1行で実行できます。
|
| NumPy | Pandasの裏側で動いている数値計算エンジンです。Pythonは本来処理速度が遅い言語ですが、NumPyが行列演算をC言語レベルで高速処理することで、数百万行に及ぶ過去30年分のレースデータも瞬時に計算可能にします。 |
| Scikit-learn | 機械学習の「道具箱」です。モデルを作るだけでなく、正しい検証を行うために不可欠です。
|
| LightGBM | 現在の競馬AI界隈で「最強」の一角を占めるアルゴリズムです。Microsoftが開発したこの勾配ブースティング決定木(GBDT)は、以下の理由から競馬データと相性が抜群です。
|
| pywin32 | Windows環境において、JRA公式データ(JRA-VAN Data Lab.)を利用するために必須となる特殊なライブラリです。Windowsのシステム機能である「COM (Component Object Model)」をPythonから制御し、公式ソフト「JV-Link」を介してデータを自動取得するパイプラインを構築します。 |
| Matplotlib / Seaborn | データの可視化ツールです。「オッズ1.5倍未満の馬が飛ぶ(4着以下になる)条件は何か?」といった仮説を立てた際、散布図やヒストグラムを描画して視覚的にエッジ(優位性)を発見するために使用します。 |
特に初心者の方が最初に注力すべきは、Pandas(パンダス)の習得です。AIモデルの精度は、アルゴリズムの良し悪しよりも「いかに質の高いデータ(特徴量)を作れるか」に依存します。「馬場状態が『重』の時の、父ディープインパクト産駒の連対率」といった複雑な条件集計を、Pandasを使って自由自在に行えるようになること。これこそが、回収率100%超えを目指すための最短ルートです。
また、最終的なモデル構築にはLightGBMを推奨します。Scikit-learnに含まれるランダムフォレストなども優秀ですが、計算速度と精度のバランス、そしてランキング学習への対応力を考慮すると、現代の競馬AI開発においてLightGBMを選ばない理由はありません。
補足:ディープラーニングの使い所
「PyTorch」や「TensorFlow」といったディープラーニング(深層学習)ライブラリは、さらに高度な分析を行う際に登場します。例えば、「馬名の響き(テキストデータ)」から期待値を算出したり、パドックの「馬体画像」から調子を判別したりする場合です。これらはテーブルデータ(表形式)の分析よりも難易度が跳ね上がりますが、独自の強み(Alpha)を見つけるための強力な武器となります。
これらのライブラリは、すべて無料で利用でき、世界中のデータサイエンティストによって日々改良されています。この「巨人の肩」に乗ることができる環境こそが、Pythonを選ぶ最大のメリットなのです。(出典:LightGBM Documentation – Read the Docs)
スクレイピングによるデータ収集の危険性と対策
ここは非常にデリケート、かつ開発者のモラルが問われる重要なパートなので、少し真剣にお伝えします。「競馬予想 ai python」や「競馬 データ収集」といったキーワードで検索すると、検索上位には Qiita や Zenn、あるいは個人の技術ブログなどがヒットします。そこでは、BeautifulSoup や Selenium、Scrapy といったPythonライブラリを駆使して、「netkeiba.com」などの大手ポータルサイトからレース結果やオッズ情報を自動収集(スクレイピング)するコードが当たり前のように紹介されています。
これらの記事は、Pythonの学習用としては面白いかもしれません。しかし、これから「勝てるAI」を本気で運用しようと考えているあなたには、安易なスクレイピングは絶対に推奨できません。それは単に「マナーが悪い」という次元の話ではなく、あなたの開発環境そのものを危険に晒し、最悪の場合は法的責任を問われるリスクすらあるからです。
大手サイトの利用規約と「アクセス遮断」の実態
特に、国内最大級の競馬情報サイトである「netkeiba.com」は、利用規約において自動化された手段によるデータ取得を厳格に禁止しています。かつては黙認されていた時期もありましたが、近年はAIブームによるアクセス過多がサーバーへの深刻な負荷となっており、運営側も対策を強化しています。
スクレイピングが引き起こす具体的なペナルティ
- IPアドレス単位での永久BAN:サイト側はアクセス頻度やリクエストのパターン(User-Agent等)を常に監視しています。スクレイピングプログラムだと検知された場合、その接続元のIPアドレスが遮断されます。これにより、プログラムが動かなくなるだけでなく、あなたのPCやスマホから普通にブラウザでサイトを閲覧することさえできなくなります。
- 威力業務妨害の懸念:短時間に数千、数万回というリクエストをサーバーに送りつける行為は、技術的には「DoS攻撃」と区別がつきません。サーバーをダウンさせたり、他の利用者のアクセスを遅延させたりした場合、「偽計業務妨害」や「威力業務妨害」として法的措置の対象になる可能性があります。
-

- YUKINOSUKE
実際に、同サイトのヘルプページには「スクレイピングによって通信制限をかけた場合、解除依頼には応じられない」旨が明記されています。一度BANされれば、その回線からのアクセス権は失われたも同然です。
(出典:netkeiba.com『データベースの閲覧ができない・通信制限がかかった(スクレイビングについて)』)
技術的な「技術的負債」とメンテナンスコスト
法的・倫理的な問題を抜きにしても、システム開発の観点から見て、Webスクレイピングは非常に「脆い(Fragile)」手法です。
WebサイトのデザインやHTML構造は、運営側の都合で頻繁に変更されます。ある日突然、<div class="race_result"> というクラス名が変更されたり、テーブルの列順が入れ替わったりすることは日常茶飯事です。そのたびに、あなたの作成したスクレイピングコードはエラーを吐いて停止します。
週末のレース直前にコードが動かなくなり、必死になってHTMLソースを目視確認し、修正パッチを当てる……そんな「イタチごっこ」に貴重な週末を費やしたいでしょうか? 本来、時間は「AIモデルの精度向上」や「新しいファクターの検証」に使われるべきです。
エンジニアとしての最適解:JRA-VAN公式データの活用
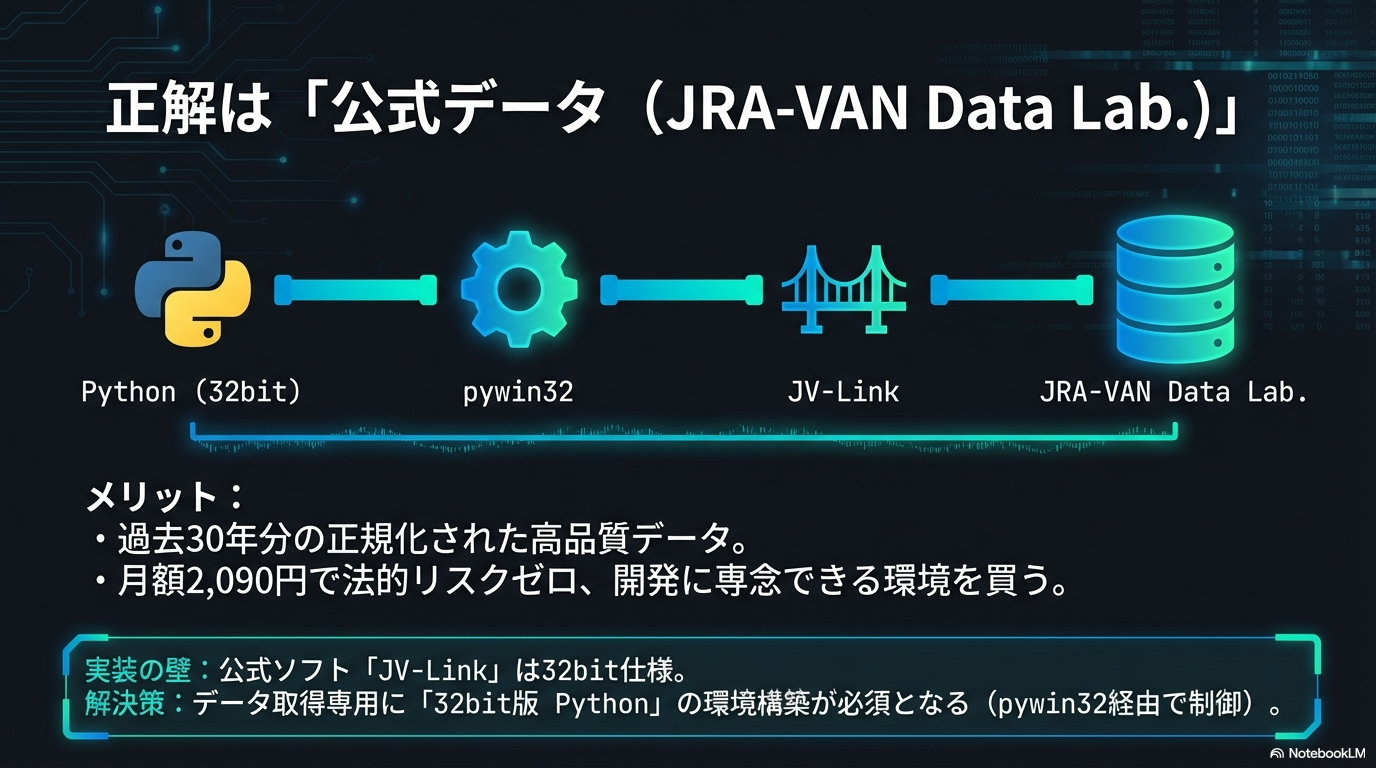
では、安全かつ確実にデータを手に入れるにはどうすればよいのでしょうか。その正解は、JRA(日本中央競馬会)の関連会社であるJRAシステムサービスが提供する公式データサービス「JRA-VAN Data Lab.」を利用することです。
JRA-VAN Data Lab.を利用するメリット
- 圧倒的なデータ品質と網羅性:1986年以降の過去30年分以上の全レースデータが、正規化された状態で蓄積されています。Web上にはない詳細な「坂路調教タイム」や「パトロールビデオ」などのデータも取得可能です。
- 法的リスクゼロの安心感:月額2,090円(税込)の有料サービスですが、これは「データを自由に利用する権利」への対価です。規約の範囲内であれば、独自ソフトの開発や分析にフル活用しても誰にも文句は言われません。
- 開発効率の向上:前述の通り、Pythonから
pywin32ライブラリを介して公式ソフト「JV-Link」を操作することで、データのダウンロードからDBへの格納までを完全自動化できます。
-
- YUKINOSUKE
「たかがデータに月額2,000円も払いたくない」と感じる方もいるかもしれません。しかし、サーバーBANのリスクに怯えながら不安定なスクレイピングを続けるコストと、公式データを堂々と使い倒してシステムを安定稼働させるメリットを天秤にかければ、答えは明白です。データソースの権利関係をクリアにし、正規の手続きで情報を得ることは、技術力以前の「プロフェッショナルとしての嗜み」と言えるでしょう。
初心者におすすめの本でプログラミングを学ぶ
Web上には無料で優れたチュートリアルが無数に存在しますが、それらはあくまで「断片的な情報の集合体」に過ぎません。これから皆さんが挑もうとしている「競馬予想AIの開発」というプロジェクトは、データの収集から整形、モデルの構築、そして評価まで、一連の流れを体系的に理解していなければゴールにはたどり着けません。そのための「地図」として、やはり体系化された「書籍」を手元に置いておくことを強くおすすめします。
私自身、最初はネットのコピペで済ませようとして何度も挫折しました。しかし、良書と出会い、基礎から積み上げ直したことで、エラーログの意味が理解できるようになり、開発スピードが飛躍的に向上しました。ここでは、私の経験に基づき、段階別に選ぶべき書籍のジャンルと、学習のポイントを具体的に解説します。
ステップ1:まずは「データ分析」に特化したPython入門書を選ぶ
「Python自体が初めて」という方が陥りやすい罠が、「Webアプリ開発向け」の入門書を選んでしまうことです。DjangoやFlaskといったフレームワークの使い方が書かれた本は素晴らしいですが、競馬予想AIを作りたい私たちにとっては遠回りです。
私たちが優先すべきは、「データ分析ライブラリ(Pandas, NumPy, Scikit-learn)」の操作に特化した書籍です。
選書のアドバイス
- 「Python 1年生」のような超入門書:まずはプログラミングへのアレルギーをなくすために、イラストが多く、薄い本を1冊読み切りましょう。「変数」「リスト」「for文」の概念さえ掴めればOKです。
- 「データ分析の教科書」系の実用書:次に、必ずPandas(パンダス)について詳しく書かれた本を選んでください。競馬データは「表形式(データフレーム)」で扱うため、Pandasの操作スキルが開発の9割を支えると言っても過言ではありません。
ステップ2:商業誌にはない「秘伝のタレ」は技術同人誌で学ぶ
ここが最も重要なポイントです。実は、Amazonや大手書店で売られている商業出版物の中には、「競馬予想AIの作り方」を専門的かつ実践的に解説した本はほとんどありません。なぜなら、ニッチすぎるうえに、スクレイピングやギャンブルというテーマが商業ベースに乗りにくいからです。
そこで私が強く推奨するのが、「技術系同人誌」の活用です。「技術書典」などのイベントや、BOOTHなどのオンラインマーケットでは、現役のエンジニアやデータサイエンティストが趣味全開で書いた「競馬AI本」が多数頒布されています。
- 「自動AI生成ツールで手軽に競馬予想AIを作ろう」
- 「JRA-VANのデータをPythonで解析する技術」
こういったタイトルの同人誌には、商業誌ではボカされがちな「JV-Linkの具体的な呼び出しコード」や「泥臭いデータクリーニングのノウハウ」が赤裸々に書かれています。これらはまさに、先人たちが血と汗で獲得した「秘伝のタレ」です。数百円〜数千円の投資で、数十時間の試行錯誤をショートカットできると考えれば、安いものです。
ステップ3:書籍のコードが動かない?「バージョンの壁」に注意
書籍で学ぶ際に、一つだけ覚悟しておかなければならないことがあります。それは「ライブラリのバージョンアップによる仕様変更」です。紙の書籍は、出版された瞬間に情報が古くなり始めます。
特にPythonのデータ分析界隈は進化が速く、数年前に出版された名著のコードが、最新の環境ではエラーで動かないということが頻繁に起こります。その代表例が、Pandasにおけるデータの追加メソッドです。
【重要】Pandasのappendメソッド廃止について
多くの古い入門書やブログ記事では、データフレームに行を追加する際にdf.append()というメソッドを使用しています。しかし、このメソッドはPandas 2.0以降で完全に削除されました。現在、同様の処理を行うにはpandas.concat()を使用する必要があります。
初心者の多くが、本に書いてある通りにappendと書いてエラーになり、「なぜ動かないんだ!」と頭を抱えてしまいます。しかし、これはあなたが悪いのではなく、技術の進歩によるものです。こうした情報は、常に公式のドキュメント(一次情報)を確認する癖をつけることで回避できます。
(出典:Pandas 2.0.0 Release Notes (Deprecations))
このように、書籍はあくまで「道しるべ」であり、実際の道路状況(ライブラリの仕様)は刻一刻と変化しています。「本にはこう書いてあるけど、今はどう書くのが正解なんだろう?」と、常に最新情報を検索しながら読み進める姿勢こそが、エンジニアとしての成長を加速させます。
まずは手堅い入門書で基礎を固め、次に技術同人誌で競馬特有の実装を学び、最後に公式ドキュメントで最新の書き方にアップデートする。この3段構えの学習フローであれば、確実に自分だけの競馬予想AIを構築できるはずです。
基礎的な予測モデルの作り方と実装の流れ
AI開発のフローは、よく「料理」に例えられます。新鮮な素材(データ)を市場から仕入れ、丁寧に下ごしらえ(前処理)をし、レシピ通りに調理(学習)して、最後に味見(評価)をする。この一連のサイクルを回すことこそが、エンジニアリングの本質です。
しかし、競馬予想AIにおいては、この工程の一つひとつに「落とし穴」があります。私自身、最初はネット上のコードをコピペして動かすだけで満足していましたが、それだけでは回収率75%(控除率の壁)を超えることは絶対にできません。ここでは、私が数々の失敗から学んだ、「負けないモデル」を作るための堅実な実装パイプラインを、Pythonの具体的なライブラリ名とセットで解説します。
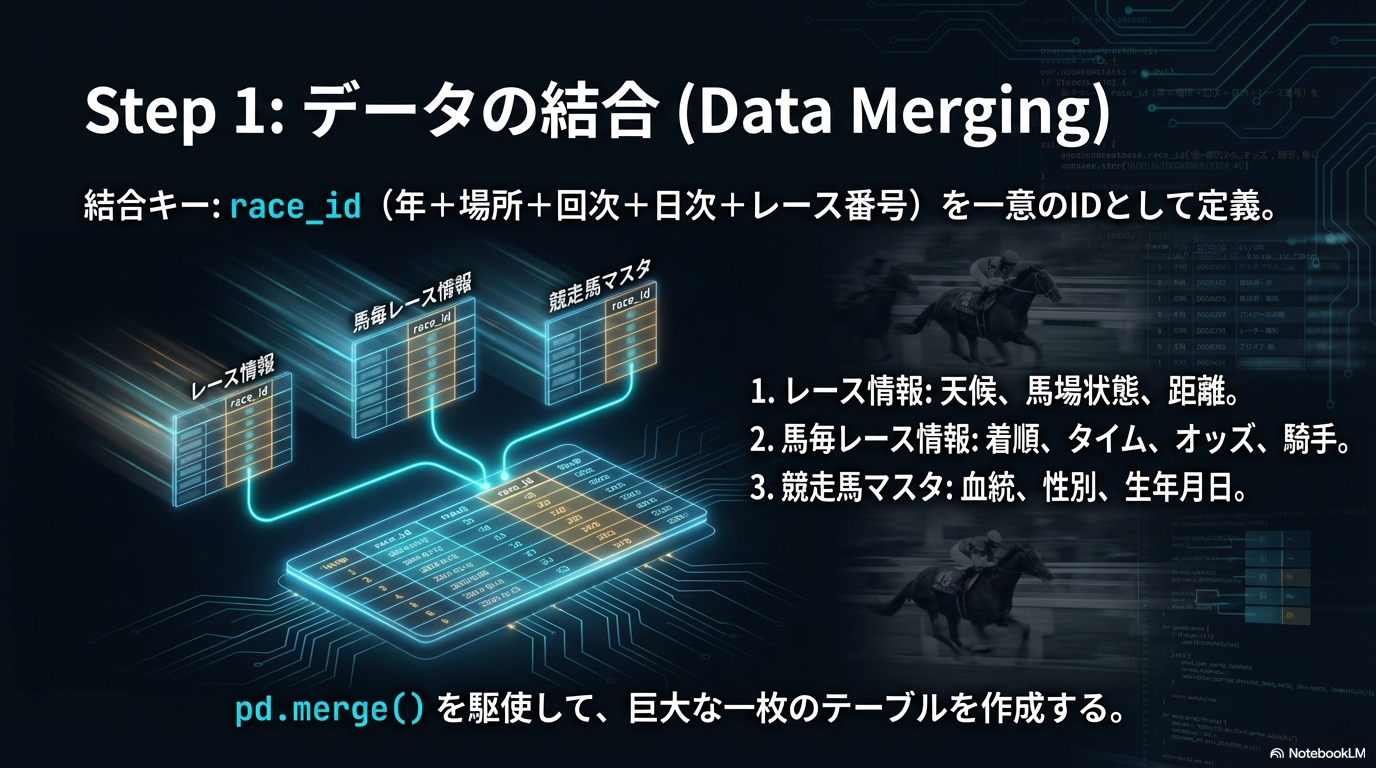
1. データの収集と結合(Merge)
まずは素材の準備です。JRA-VAN Data Lab.から取得したデータは、通常複数のCSVファイル(またはデータベースのテーブル)に分かれています。これらをPythonのPandasライブラリを使って一つにまとめる作業から始まります。
基本的には、以下の3つの主要データをrace_id(レースID)という共通のキーを使って結合(Merge)します。
| データ種類 | 主な項目 | 役割 |
|---|---|---|
| レース情報 (jvd_ra) |
日付, 競馬場, 距離, トラック種別(芝/ダート), 天候, 馬場状態 | 「どんな環境でレースが行われるか」を定義します。 |
| 馬毎レース情報 (jvd_se) |
馬番, 騎手ID, 負担重量, 確定着順, 走破タイム, オッズ | 予測の対象となる「結果」と、各馬の個別の条件です。 |
| 競走馬マスタ (jvd_um) |
馬名, 生年月日, 性別, 毛色, 父馬ID, 母馬ID | 馬の基本的な属性や血統情報を含みます。 |
-
- YUKINOSUKE
ここで重要なのは、「レースID」を一意の識別子として正しく設計することです。JRAのデータ仕様では「年+場所+回次+日次+レース番号」で構成されますが、これを文字列として結合し、Pandasのpd.merge()関数を使って大きな一枚のテーブル(DataFrame)を作成します。
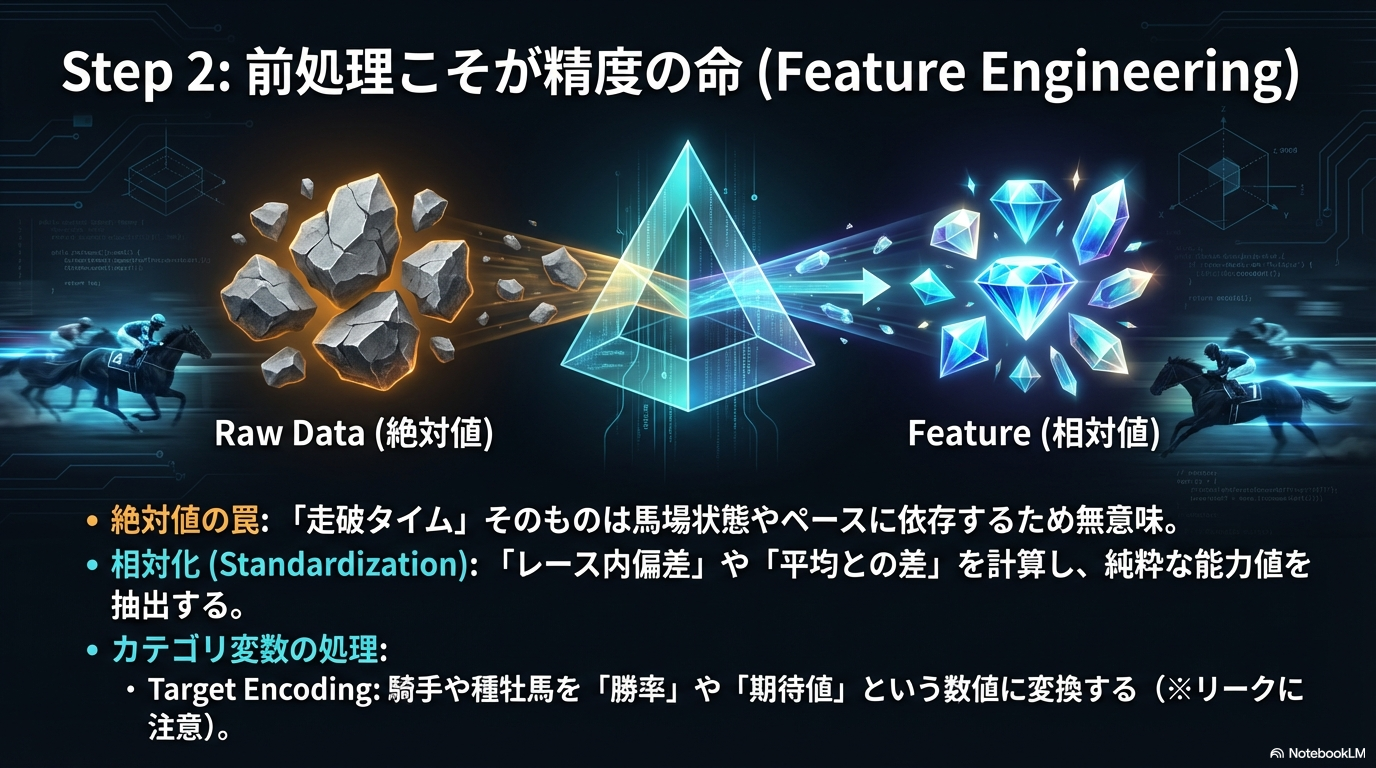
2. 前処理・特徴量エンジニアリング(Preprocessing)
-
- YUKINOSUKE
ここがAIの精度を決定づける最重要フェーズです。「Garbage In, Garbage Out(ゴミを入れたらゴミしか出てこない)」という格言の通り、生のデータをそのまま学習させてもAIは賢くなりません。
- 欠損値の処理:
地方競馬からの転入馬や、海外レースのデータが含まれる場合、過去のタイムや体重データが「欠損(NaN)」になっていることがあります。これを平均値で埋めるのか、-1などの異常値として扱うのか、あるいはその行ごと削除するのかを決定します。LightGBMなどの木構造モデルは欠損値をそのまま扱える利点がありますが、意図しない挙動を防ぐためにも明示的な処理を推奨します。
- カテゴリ変数の数値化:
「東京競馬場」「良馬場」「ルメール」といったコンピュータが理解できない文字情報を数値に変換します。- Label Encoding:単純にID番号(例:東京=1, 中山=2)に変換する方法。
- Category Type:Pandasの
astype('category')を使用し、LightGBMに「これはカテゴリ変数だよ」と教えてあげる方法。これが最も手軽で高性能です。
- データの相対化(Standardization):
これが初心者が最も見落とすポイントです。例えば「走破タイム:2分00秒」という絶対値は、スローペースのレースとハイペースのレースでは意味が全く異なります。
そこで、「そのレースの平均タイムとの差(偏差)」や「上がり3ハロンの順位」といった、レース内での相対的な位置づけを表す特徴量を作成します。これにより、AIは「タイムそのもの」ではなく「その馬が周囲と比べてどれだけ秀でていたか」を学習できるようになります。
3. 時系列を考慮したデータ分割(Time Series Split)
モデルを作る際、データを「学習用(Train)」と「テスト用(Test)」に分けますが、ここでランダムにシャッフルしてはいけません。なぜなら、競馬は「過去のデータから未来を予測する」ものだからです。
もしランダムに分割して、「2023年の有馬記念」を学習データに入れ、「2023年のジャパンカップ(有馬記念より前のレース)」をテストデータにしてしまった場合、AIは「未来の馬の成長や調子」を知った状態で過去を予測することになります。これは「リーク(Data Leakage)」と呼ばれる致命的なミスです。
未来の情報をカンニングさせない!
必ず「日付」でデータをソートし、時系列順に分割してください。
例:
・学習データ:2015年 ~ 2021年
・テストデータ:2022年 ~ 2023年
Scikit-learnのTimeSeriesSplitクラスを活用すると、この検証を厳密に行うことができます。
-

- YUKINOSUKE
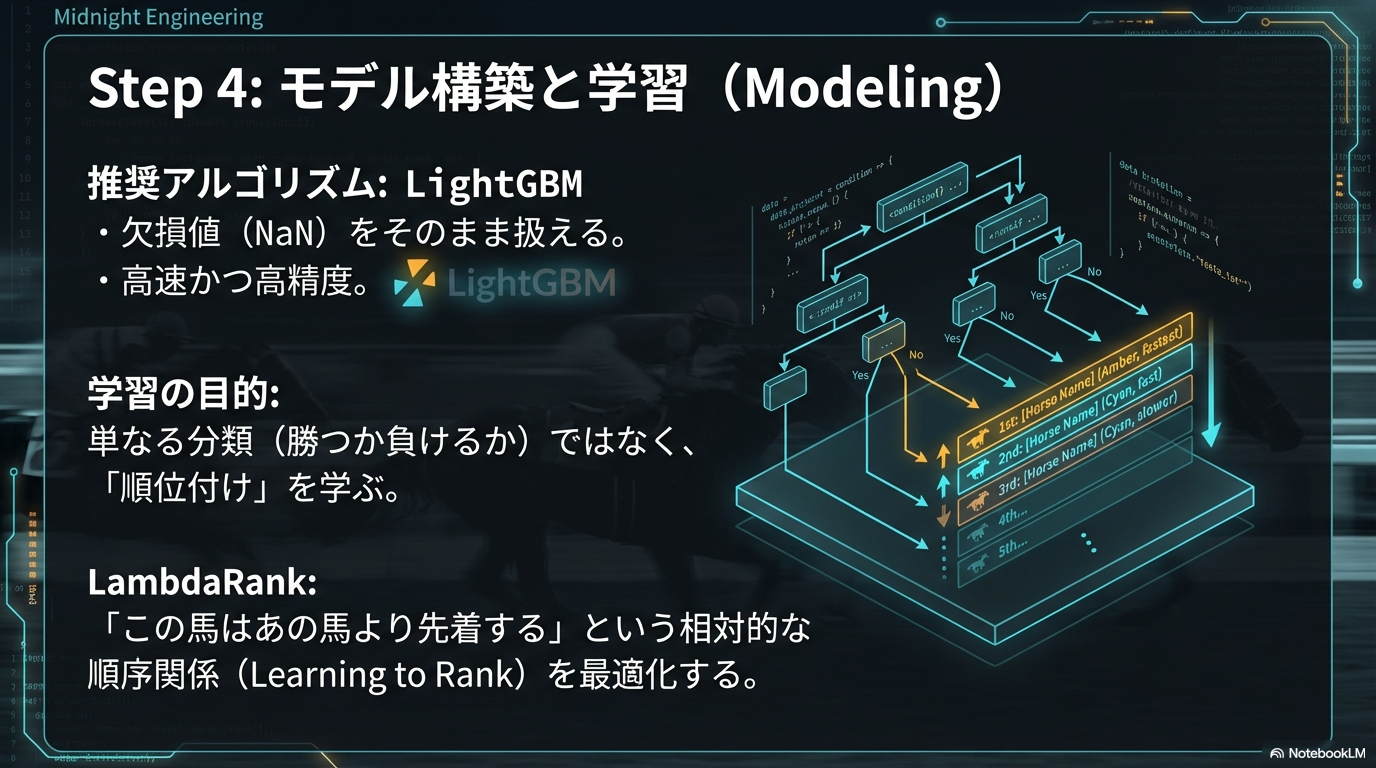
4. モデル学習(Modeling)と目的関数の設定
-
- YUKINOSUKE
データが整ったら、アルゴリズムに学習させます。現在はLightGBMがデファクトスタンダードです。最初のステップとしては、複雑な順位予測ではなく、シンプルな「二値分類(Binary Classification)」から始めることを強くおすすめします。
- 目的変数(Label):1着なら
1、それ以外なら0(または3着以内なら1)。 - 目的関数(Objective):
binary(二値分類)またはxentropy。
Pythonでの実装イメージとしては、前処理済みのデータをlgb.Dataset形式に変換し、lgb.train()メソッドを呼び出すだけです。この段階では、ハイパーパラメータ(学習率や木の深さなど)の細かいチューニングに時間をかけるよりも、「特徴量を追加・削除したときに精度がどう変わるか」という実験のサイクルを回すことに注力してください。
5. 評価(Evaluation)とシミュレーション
学習が終わったら、テストデータを使って評価を行います。ここで「正解率(Accuracy)」だけを見てはいけません。競馬は18頭中17頭が負けるゲームなので、AIが「全頭負ける」と予測すれば、それだけで的中率94%(17/18)が出てしまうからです。
見るべき指標は以下の通りです。
- AUC(Area Under the Curve):不均衡データにおけるモデルの識別能力を測る指標。0.7以上あれば優秀と言えます。
- 回収率シミュレーション:これが最も重要です。AIが出した「勝つ確率(スコア)」が高い順に馬券を買った場合、資金がどう増減するかをシミュレーションします。
回収率100%の壁を超えるために
単に「当たる確率が高い馬」を買うと、必然的に1番人気(オッズが低い馬)ばかりを買うことになり、回収率は75%〜80%に収束します。
真に勝つためには、「AIの予測確率は高いのに、オッズは美味しい(過小評価されている)馬」を見つけ出すロジックを評価フェーズに組み込む必要があります。
このプロセスを何度も繰り返し、特徴量を磨き上げていく作業こそが、競馬予想AI開発の醍醐味であり、エンジニアとしての腕の見せ所なのです。
(出典:Scikit-learn公式ドキュメント『TimeSeriesSplit』)
地方競馬のデータ取得とAPI活用のポイント
-

- YUKINOSUKE
ここまで主に中央競馬(JRA)のシステム構築について解説してきましたが、実は私たちが狙うべき「青い海(ブルーオーシャン)」は地方競馬(NAR)に広がっています。中央競馬は週末だけですが、地方競馬はほぼ毎日、全国のどこかで開催されています。つまり、「毎日が実験と実践の場」になり得るのです。
しかし、ここで一つ大きな壁にぶつかります。それが「データの取得難易度」です。JRAには「JRA-VAN」という世界に誇れる統一データインフラがありますが、地方競馬には全く同じ使い勝手のものは存在しません。多くのエンジニアがここで挫折するのですが、逆に言えば、「ここを突破できればライバルが激減する」ということでもあります。
地方競馬データの「三種の神器」と接続方法
Pythonで地方競馬のデータを扱う場合、選択肢は大きく分けて3つあります。それぞれの特徴を理解し、自分の技術レベルに合った方法を選ぶことが成功への鍵です。
| 取得方法 | データ品質 | 難易度 | YUKINOSUKEの評価 |
|---|---|---|---|
| 地方競馬DATA (UmaConn) | 最高(公式) | 高 | 本気で開発するならこれ一択。PythonからCOM経由で公式データを直接叩けます。 |
| PC-KEIBA(SQLブリッジ) | 高 | 中 | 無料ソフトを介してMySQLなどにデータを流し込み、Pythonで読む方法。最も現実的で管理しやすい。 |
| 楽天競馬 / 海外API | 低〜中 | 低 | 投票には便利ですが、過去の血統や坂路調教などの「学習用データ」としては不十分なことが多いです。 |
隠れた名ツール「UmaConn」と「NV-Link」をハックする
これが今回、私が最も伝えたかった技術的なキモです。JRA-VANに「JV-Link」があるように、実は地方競馬にも「UmaConn(ウマコン)」というミドルウェアが存在します。これに含まれる通信モジュール(通称:NV-Link)を利用することで、Pythonから地方競馬の公式データを取得可能になります。
技術的な仕組みはJV-Linkとほぼ同じで、WindowsのCOM(Component Object Model)を利用します。しかし、ここで一つ大きな罠があります。
【重要】32bitの壁に注意
UmaConnが提供するDLL(`NVDTLab.dll`など)は、基本的に32bitアプリケーションとして動作します。そのため、普段使っている64bit版のPythonから呼び出そうとすると「クラスが登録されていません」といったエラーで弾かれます。
これを解決するには、32bit版のPython環境を別途インストールするか、仮想環境を構築する必要があります。私はこれに気付くまでに丸3日溶かしました…。
PC-KEIBAを「データハブ」として利用する賢い戦略
「32bit環境とかCOM操作とか、ちょっと面倒だな…」と思ったあなた。正解です。正直、PythonでCOMを直接叩くのはバグの温床になりやすいです。そこでおすすめなのが、「PC-KEIBA Database」という無料ソフトを中間サーバーとして使う方法です。
- 「地方競馬DATA(有料)」を契約する。
- 「PC-KEIBA」を使って、データをPostgreSQLやMySQLなどのデータベースに取り込む。
- Python(pandas)からは、
sqlalchemyなどを使ってそのデータベースを読みに行く。
この構成にすると、Python側は純粋なデータ分析コードだけに集中でき、面倒なデータ更新や差分管理はソフトに任せることができます。システムとしての堅牢性は、この「疎結合」な構成の方が圧倒的に高いです。
なぜ地方競馬こそAIなのか?
苦労してデータを集める価値は十分にあります。地方競馬は中央競馬に比べて「情報の非対称性」が大きいためです。
- オッズの歪み:参加者が少ないため、特定の馬に過剰な投票が入ったり、逆に実力馬が放置されたりしやすい。
- 騎手の格差:地方競馬では「このコースはこの騎手」といった職人的な偏りが顕著に出ます。AI(Target Encoding)はこの傾向を捕まえるのが大得意です。
- 難解なコース適性:高知競馬の「不良馬場」や、帯広の「ばんえい競馬」など、特殊な環境要因が多く、人間が感覚で処理しきれない部分を数値化することでエッジ(優位性)が生まれます。
地方競馬AI開発のロードマップ
- まずは「地方競馬DATA」の会員になり、公式データへのアクセス権を確保する。
- 「PC-KEIBA」等のツールを使って、ローカル環境に過去5年分のDBを構築する。
- 南関東(大井・川崎・船橋・浦和)など、データ量が多くレベルの高い競馬場からモデルを作り始める。
- 高知競馬の「一発逆転ファイナルレース」など、人間が予想を放棄したくなるレースこそAIの主戦場にする。
データ取得のハードルが高いということは、それだけ参入障壁が高いということ。ここを乗り越えた先には、手つかずのデータ資源が眠っています。
(出典:地方競馬全国協会(NAR)公式サイト)
ちなみに、地方競馬のAIについては、こちらの記事地方競馬はAI最強?おすすめアプリと回収率を上げる予想法でも詳しく解説しています。「地方競馬のAI」をもっと深く知りたい方は、ぜひチェックしてみてください。
45万円のAI講座[E資格]を月額3,000円で始められる【ラビットチャレンジ】 ![]()
![]()
競馬予想AIをPythonで実装して回収率を上げる
基礎ができたら、次はいよいよ「勝てるAI」を目指すフェーズです。単に的中率(Accuracy)を上げるだけでは、競馬で勝つことはできません。なぜなら、オッズが低い本命ばかり当てても、トリガミ(当たっても損する状態)になるからです。回収率(Profit)を追求するには、金融工学的なアプローチや高度な特徴量エンジニアリングが必要になります。ここからは、中級者以上向けに少し踏み込んだ技術的な話をします。
JRAの公式データを自動取得する方法
本格的なAI運用を目指すなら、毎週手動でデータをダウンロードしてCSVに変換し、それをPandasで読み込む……といった「手作業」からは卒業しなければなりません。データサイエンスの本質はモデルの改善にあり、データの準備ごときに時間を奪われていては、いつまで経っても回収率は向上しないからです。
私が推奨するのは、Windows専用のミドルウェアである「JV-Link」をPythonから直接操作し、データ取得を完全自動化する技術です。これを実現するのが、PythonとWindowsのAPIを繋ぐ強力なライブラリ、pywin32です。
Windows COMとPythonの架け橋「pywin32」
JRA-VANが提供する「JV-Link」は、Windowsの伝統的な技術である「COM(Component Object Model)」として実装されています。簡単に言えば、ExcelやWordを外部プログラムから操るのと同じ仕組みで、PythonからJV-Linkという「ロボット」に指令を出し、JRAのサーバーからデータを引っ張ってこさせるわけです。
しかし、ここで多くのエンジニアが最初に躓く巨大な落とし穴があります。それは「Pythonのビット数」です。
【重要】32bit版Pythonの環境構築が必須
JV-Linkは古い規格で作られており、32bit版のアプリケーションとして動作します。そのため、普段あなたが使っているであろう64bit版のPythonから呼び出そうとしても、「クラスが登録されていません」といったエラーが出て動きません。このデータ取得専用に、別途32bit版のPython環境(仮想環境など)を構築する必要があります。私はこれで丸3日悩み続けました。
JV-Link制御の核心:Dispatchとイベント駆動
環境が整ったら、次はいよいよ実装です。PythonからJV-Linkを制御するためには、いくつかの重要なメソッドと概念を理解する必要があります。
まず、インスタンスの生成にはwin32com.client.Dispatchメソッドを使用しますが、私はより堅牢なEnsureDispatchの使用を強く推奨します。
- EnsureDispatchの使用:
通常のDispatchは動的に接続しますが、win32com.client.gencache.EnsureDispatch("JVDTLab.JVLink")を使うことで、静的な型情報(MakePy)を事前に生成・キャッシュします。これにより、メソッド呼び出しのオーバーヘッドが減り、動作が安定するほか、IDEでの補完が効きやすくなるメリットがあります。
次に、データのダウンロード処理です。JV-Linkの通信は非同期(バックグラウンド)で行われるため、単に「ダウンロード開始」の命令を送っただけでは、いつ終わったのか分かりません。ここで「イベント駆動プログラミング」の知識が必要になります。
イベントシンク(Event Sink)の実装
Python側で「JV-Linkからの連絡を待つ専用のクラス」を作ります。これをイベントシンクと呼びます。
- JV-Linkがダウンロードを終えると、
OnDownloadCompleteというイベントを発火します。 - Python側のイベントシンクがそれをキャッチし、「完了しました、次の処理へ進みます」とフラグを立てます。
- この仕組みがないと、ダウンロードが終わっていないのにデータを読み込もうとしてエラーになるか、無限ループで待機することになります。
苦行にして最大の難所:固定長データのバイト解析
無事にデータが降りてきたとして、次に待ち受けているのが「データの解読」です。JRA-VANから送られてくるデータは、扱いやすいJSONやCSVではありません。昔ながらの固定長テキストデータ(Fixed-Width Text)です。
例えば、「レース情報」というデータが送られてきた場合、以下のようなルールでバイト単位で区切る必要があります。
| バイト位置 | 項目名 | データの意味 |
|---|---|---|
| 1~10byte | データ区分 | “RA”(レース詳細)などの識別子 |
| 11~18byte | 開催年月日 | “20231224” のような文字列 |
| 19~20byte | 競馬場コード | “06”(中山)などのコード値 |
| … | … | … |
これをPythonの文字列スライス機能(slicing)を使って、race_date = line[10:18]のように一行一行切り出していくパーサー(解析プログラム)を書く必要があります。JRA-VANが提供している「JV-Data仕様書」は電話帳のような分厚さ(PDFで数千ページ)ですが、これを読み解きながら辞書型やPandasのDataFrameに変換するコードを書いている時こそ、エンジニアとしての基礎体力が試される瞬間です。
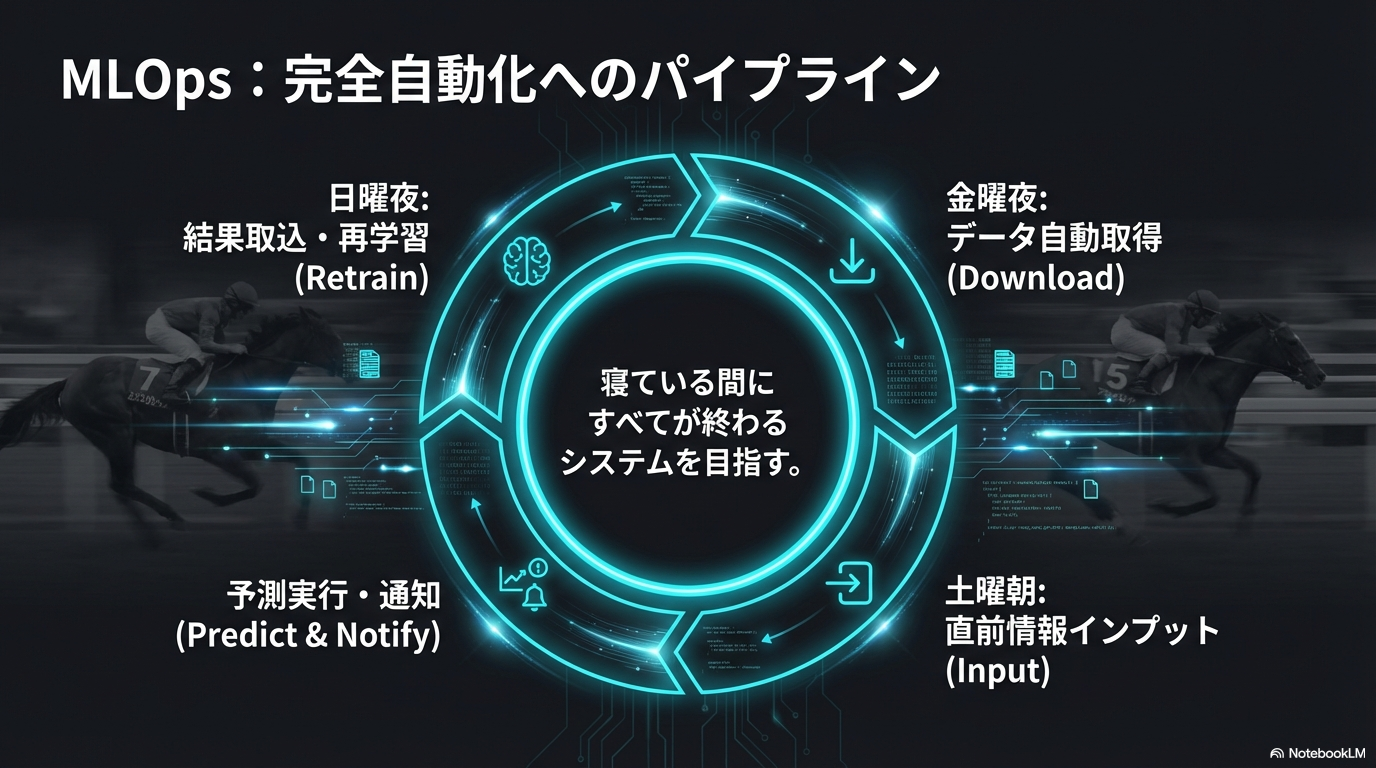
完全自動化への道:金曜夜のパイプライン構築
-
- YUKINOSUKE
これらのハードルを乗り越えた先には、素晴らしい自動化ライフが待っています。私が構築したシステムでは、タスクスケジューラを使って以下のようなパイプラインを稼働させています。
- 金曜日の夜23時:自動スクリプトが起動。週末の「出馬表データ」と「調教データ」を取得。
- 土曜日の朝9時:当日の「馬体重データ」や「天候・馬場状態」の速報値を取得し、予測モデルにインプット。
- 朝9時10分:AIが全レースの推奨買い目を算出し、私のLINEに通知を送る。
- レース確定後:結果データを自動取得し、データベースに格納。モデルの再学習用データとして蓄積。
この「寝ている間に全てが終わっている」感覚こそ、エンジニアとしての勝利を感じる瞬間です。手動でポチポチとデータを集めているライバルたちが寝不足で予想している間に、私たちは優雅にコーヒーを飲みながら、AIがはじき出した高期待値の馬をチェックするだけ。この技術的優位性(エッジ)こそが、長期的な回収率を支える基盤となるのです。
補足:Macユーザーの方へ
残念ながらJV-LinkはWindows専用です。Macユーザーの方がこの環境を構築する場合、Parallels Desktopなどの仮想マシンを利用するか、安価なWindowsの中古PCを「データ取得専用サーバー」として24時間稼働させておくのが現実的な解となります。
回収率100%超えを目指すファクター分析
AIモデルの精度、ひいては最終的な回収率を決定づける最大の要因は、アルゴリズムの選択ではなく「特徴量エンジニアリング(Feature Engineering)」の質にあります。多くのエンジニアが最初に陥る罠は、JRA-VANなどから取得したデータをそのまま、右から左へとモデルに流し込んでしまうことです。
しかし、断言します。生のデータ(Raw Data)をそのまま使っても、回収率が100%を超えるAIは絶対に作れません。なぜなら、競馬データは文脈によって意味が大きく変わる「ノイズの塊」だからです。ここでは、私が無数の失敗から学んだ、プロレベルのファクター生成術を深掘りします。
1. 絶対値の罠と「相対化」の魔術
例えば、「走破タイム」という指標一つとっても、その数値の絶対値にはほとんど意味がありません。芝2000mのレースで「2分0秒0」というタイムが出たとしましょう。これは速いでしょうか?遅いでしょうか?
- 開幕週のパンパンの良馬場なら「平凡なタイム」かもしれません。
- 雨でぬかるんだ重馬場なら「驚異的なレコード」かもしれません。
- スローペースでラストの瞬発力勝負になったレースなら、タイム自体は遅くても馬の能力は高いかもしれません。
このように、外部要因(馬場状態、天候、ペース、トラックバイアス)によって歪められた絶対値をそのままAIに学習させると、モデルは「雨の日は能力が低い」という誤った相関を覚えてしまいます。これを防ぐために必須となるのが徹底した「相対化(Standardization)」です。
具体的には、Pandasのgroupby機能を駆使して、レース単位での偏差値を算出します。
実装すべき相対化ロジック(例)
(その馬のタイム - そのレースの平均タイム) ÷ そのレースのタイム標準偏差
この「Zスコア」化されたタイムこそが、環境要因をキャンセルした馬の純粋な能力値です。これにより、重馬場での辛勝も、高速馬場での大敗も、統一された基準で比較可能になります。
-

- YUKINOSUKE
2. カテゴリ変数を武器にする「Target Encoding」
次に問題になるのが、騎手コード、種牡馬コード、調教師コードといった「カテゴリ変数」の扱いです。これらは数値としての大小関係に意味がないため、通常はOne-Hot Encoding(ダミー変数化)を行いますが、競馬データでこれをやると悲惨なことになります。
JRAには数千頭の競走馬、数百人の騎手がいます。これらを全てOne-Hot化すると、特徴量の次元数が数千〜数万に膨れ上がり、計算コストが爆増するだけでなく、「次元の呪い」によってモデルの精度が劇的に低下します。
そこで最強の武器となるのがTarget Encoding(Mean Encoding)です。これは、カテゴリ変数を「そのカテゴリにおける目的変数の平均値」に置換する手法です。
- 「ルメール騎手」 → 「0.254」(過去の勝率)
- 「ディープインパクト産駒」 → 「0.128」(過去の勝率)
こうすることで、数千次元のスパースなデータを、たった1列の高密度な数値データに圧縮できます。LightGBMなどの勾配ブースティング木モデルにおいては、この手法が極めて有効に機能します。
3. 最大の敵「リーク」とSmoothing処理
しかし、Target Encodingには初心者が必ず踏む地雷があります。それが「リーク(Data Leakage)」です。もし、学習データを作成する際に、対象となるレースの結果を含めて平均値を計算してしまったらどうなるでしょうか?
AIは「この馬は勝率100%の騎手が乗っているから勝つ」と予測しますが、その勝率100%の原因は「まさに今予測しようとしているレースで勝ったから」なのです。これはカンニングと同じで、テストデータでは全く通用しないモデルが出来上がります。
これを防ぐためには、以下の2つの高度な処理をPythonで実装する必要があります。
| 手法 | 概要とPythonでの実装ポイント |
|---|---|
| Out-of-Fold (OOF) | 学習データをK個のグループに分割(K-Fold)し、「自分以外のグループ」のデータを使って平均値を計算します。これにより、自分自身の未来の結果を参照することを物理的に防ぎます。 |
| Smoothing | 騎乗回数が1回で1勝した騎手は勝率100%になりますが、これをそのまま信用するのは危険です。そこで、全体の平均勝率(事前分布)と混ぜ合わせることで数値をなだらかにします。 Pythonの category_encodersライブラリを使えば、このスムージング処理をパラメータ一つで実装可能です。 |
(出典:PyPI『category-encoders』公式ドキュメント)
このように、回収率100%を超えるAIを作るということは、単にアルゴリズムを回すことではなく、「いかにしてデータからノイズを取り除き、純粋な情報を抽出するか」という泥臭いエンジニアリングの積み重ねなのです。
LightGBMやディープラーニングの活用
アルゴリズムの選定は、AI開発における「エンジン選び」に相当します。ここを間違えると、どんなに良いガソリン(データ)を入れてもスピードが出ません。現在、Kaggleなどのデータ分析コンペティションや、実務レベルの競馬予測において、事実上の世界標準(デファクトスタンダード)となっているのがLightGBMです。
LightGBMは「勾配ブースティング決定木(GBDT)」という手法を、Microsoftが改良・高速化したライブラリです。なぜこれが競馬予想において最強と呼ばれるのか、その理由は単なる予測精度の高さだけではありません。競馬データ特有の「汚さ」や「複雑さ」に対する適応力が圧倒的に高いからです。
LightGBMが競馬予想に向いている技術的理由
- 欠損値(NaN)の自動処理:競馬データは「初出走で過去タイムがない」「地方競馬出身で坂路タイムがない」といった欠損だらけです。LightGBMは欠損値を「情報」として扱い、最適な分岐方向を学習してくれます。
- カテゴリ変数の高速処理:騎手IDや種牡馬IDのような膨大なカテゴリ変数を、One-Hotエンコーディングせずに直接(fisher-yatesアルゴリズム等を応用して)処理できるため、メモリ効率が良く学習が高速です。
- 過学習の抑制:リーフワイズ(Leaf-wise)という成長戦略を採用しており、データ数が少ない条件でも精度を出しつつ、適切なパラメータ設定で過学習を防ぎやすい特徴があります。
そして、LightGBMを使う最大のメリットが、LambdaRankという学習目的関数の存在です。通常の回帰モデル(Regression)は「走破タイム」などの絶対値を予測し、分類モデル(Binary)は「勝つ確率」を予測します。しかし、競馬の本質は「タイム」ではなく「他馬との相対的な着順」を争うゲームです。
LambdaRankは、検索エンジンの「検索結果の並び替え」に使われる技術(Learning to Rank)を応用したものです。レースIDごとに馬をグループ化し、「このレース内でA馬はB馬よりも上位に来るべき」というペアワイズ(2者間)の順序関係を最適化します。具体的には、NDCG(Normalized Discounted Cumulative Gain)という指標を最大化するように勾配を計算するため、単に「当てる」だけでなく「上位に来る馬を正確に上位にランク付けする」能力が飛躍的に向上します。
(出典:Microsoft Research『From RankNet to LambdaRank to LambdaMART: An Overview』)
ディープラーニング(Deep Learning)の真の使い所
一方で、PyTorchやTensorFlowを用いたディープラーニング(ニューラルネットワーク)は、単純な表形式データではLightGBMに劣ることが多いのが現実です。しかし、以下の3つの領域では圧倒的な力を発揮します。
- Entity Embedding(埋め込み表現):騎手IDや調教師IDを数十次元のベクトルに変換し、「ルメール騎手とデムーロ騎手はベクトルが似ている(=特性が近い)」といった意味的な関係性を学習させることができます。
- 時系列データの解析:過去5走の着順や通過順位(例:10-10-8-3)といったシーケンスデータを、RNN(LSTM)やTransformerに入力することで、馬の「調子の波」や「脚質の変化」を文脈として捉えられます。
- 非構造化データの活用:馬体写真からの画像診断や、厩舎コメント・ニュース記事の自然言語処理(NLP)を行い、それを特徴量として取り込めるのはディープラーニングだけの特権です。
私の推奨する最強の構成は、「LightGBMをメインエンジンにし、ディープラーニングで生成した特徴量を入力する」、あるいは「両者の予測結果をスタッキング(アンサンブル学習)する」というハイブリッド戦略です。互いの弱点を補完し合うことで、単独モデルでは超えられない「回収率の壁」を突破する可能性が生まれます。
血統データをグラフ化して特徴量に組み込む
競馬予想において、古くから最も重視され、かつ最もデータ化が難しいとされる要素、それが「血統」です。多くの競馬ファンやトラックマンは「この馬はディープインパクト産駒だから瞬発力がある」や「母の父がストームキャットだからスピードの持続力がある」といった定性的な評価を日常的に行っています。
しかし、従来の一般的なAI開発、特に初心者が最初に作るモデルでは、血統データは非常に粗末に扱われがちです。多くの場合、「父馬ID」や「母父馬ID」を単なるカテゴリ変数として扱い、One-Hot Encoding(ダミー変数化)する程度に留まっています。これでは、「父がディープインパクトなら1、そうでなければ0」という単純なフラグ処理しかできず、「ディープインパクトとブラックタイドは全兄弟(父も母も同じ)であり、遺伝的には非常に近い」といった、血統表の奥深くに眠る構造的な情報をAIに伝えることができません。
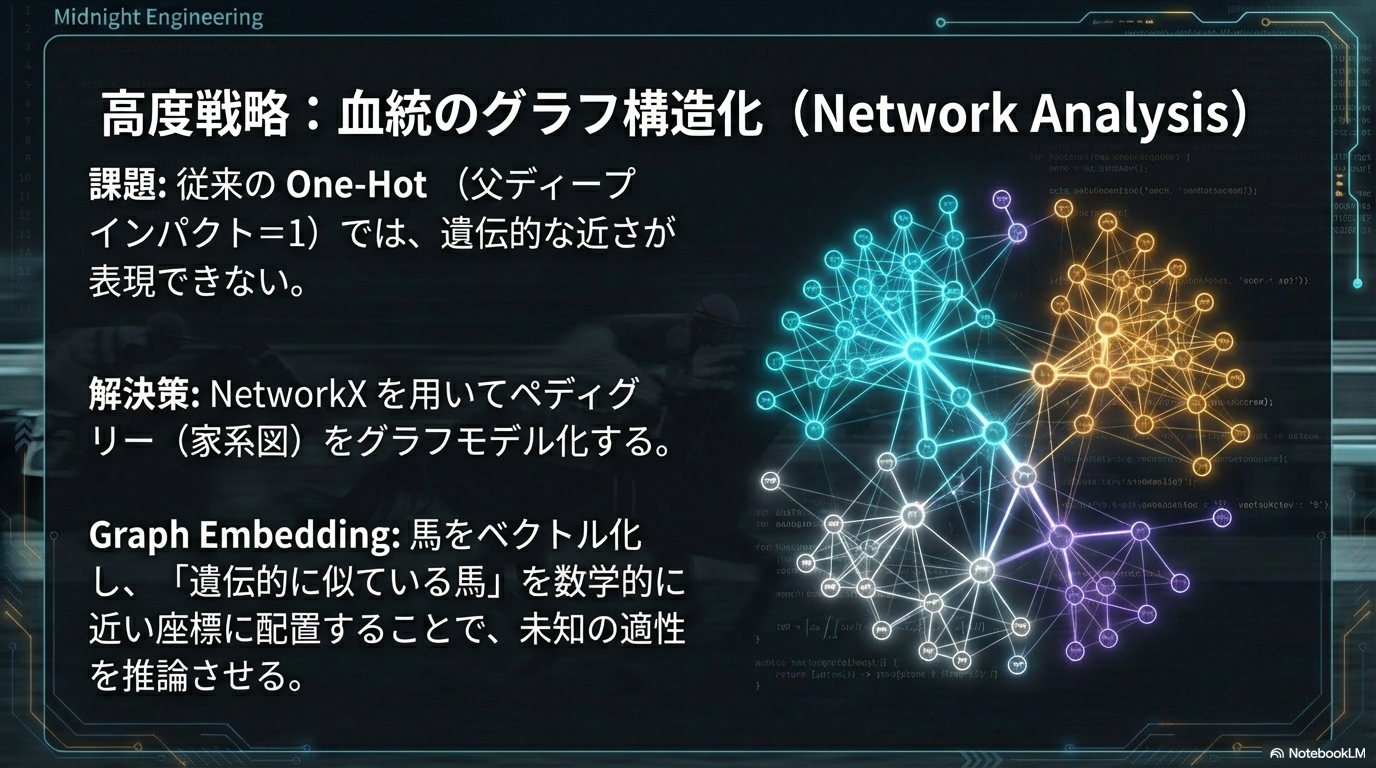
そこで、私が現在最も力を入れて研究しており、かつ回収率向上に直結すると確信しているのが、血統を「グラフ構造(ネットワーク)」として捉えるアプローチです。これは、もはや単なるデータ分析の域を超え、バイオインフォマティクス(生物情報科学)の領域に近い手法です。
NetworkXによるペディグリー(家系図)のモデリング
-
- YUKINOSUKE
Pythonには、NetworkXというグラフ理論を扱うための非常に強力なライブラリが存在します。これを利用することで、複雑に絡み合った数万頭の競走馬の血縁関係を、コンピュータ上で計算可能なネットワークとして再現することができます。
具体的には、以下のように血統を数学的なモデル(有向非巡回グラフ:DAG)に落とし込みます。
- ノード(Node): 1頭1頭の馬(父、母、祖父母、曾祖父母…)。
- エッジ(Edge): 親から子へと伸びる「遺伝子の流れ」を表す線。
このようにモデル化することで、全競走馬は巨大な一つの家系図ネットワークの一部として表現されます。こうなれば、もはや「名前」や「ID」は重要ではありません。ネットワーク内での「位置」や「繋がり方」そのものを計算できるからです。
グラフ化によって計算できる指標の例
- 次数中心性(Degree Centrality): その馬がどれだけ多くの子孫を残しているか(=種牡馬としての繁栄度)。
- 媒介中心性(Betweenness Centrality): 異なる血統グループ同士を繋ぐ「ハブ」としての役割を果たしているか。これが高い馬は、異なる系統の血を融合させるキーホースである可能性があります。
- 近交係数(Inbreeding Coefficient): グラフ上のパス(経路)を探索することで、「3代前と4代前に同じ先祖がいる(3×4のクロス)」といったインブリードの濃さを自動計算できます。
血統のベクトル埋め込み(Graph Embedding)
さらに一歩進んだ技術として、私が最も可能性を感じているのが「グラフ埋め込み(Graph Embedding)」です。これは、自然言語処理の技術(Word2Vecなど)を応用したもので、Node2VecやGraph Neural Networks (GNN)といったアルゴリズムを使用します。
通常、AIは「サンデーサイレンス」という文字列の意味を理解できません。しかし、グラフ埋め込みを行うと、血統ネットワーク上のすべての馬を、例えば「64次元の数値ベクトル」に変換することができます。
ベクトル化のイメージ
ベクトル化に成功すると、数学的な空間の中で「遺伝的に似ている馬」は「近い座標」に配置されるようになります。
例えば、「ディープインパクトのベクトル」と「ブラックタイドのベクトル」のコサイン類似度を計算すると、0.95(非常に似ている)という結果が出たり、「サドラーズウェルズ系」の馬たちは空間の一箇所に固まったりといった現象が起きます。
これにより、AIは以下のような高度な推論が可能になります。
- 未知の種牡馬の評価: 新種牡馬の産駒がデビューした際、データが少なくても、その父や母のベクトルを参照することで、「この馬はハーツクライ産駒に近い適性を持つはずだ」と推測できる。
- ニックス(配合の相性)の発見: 「父ベクトルA」と「母父ベクトルB」を組み合わせた合成ベクトルが、過去のG1馬のベクトルと類似しているかどうかを判定できる。
- 非構造化データの数値化: 「良血馬」という人間特有の感覚を、「中心性が高く、かつ成功した馬のベクトルに近い」という数学的な確信に変換できる。
ここまで実装するのは簡単ではありませんが、JRA-VANから取得した血統データをPythonでグラフ化し、特徴量としてLightGBMなどのモデルに組み込むことができれば、ライバル(他のAI開発者や一般の馬券購入者)に対して圧倒的な情報アドバンテージを持つことができます。まさに、データサイエンスの論理と、血統という競馬のロマンが融合する瞬間です。
競馬予想AIをPythonで開発する際のまとめ
ここまで、Pythonを活用した競馬予想AIの構築について、環境設定からアルゴリズムの選定、そして泥臭いデータ処理の裏側まで、かなりマニアックな技術論を交えて解説してきました。おそらく、最初はこの情報の多さに圧倒されたかもしれません。しかし、一つひとつの技術は、現代のデータサイエンスにおいて標準的なものばかりです。競馬という「不確実性の塊」にロジックで挑むこのプロジェクトは、あなたのエンジニアリングスキルを飛躍的に高める最高の題材となるはずです。
最後に、これから開発をスタートするあなたが、道に迷わず最短距離で「回収率100%超え」という頂を目指すためのロードマップを、重要なポイントに絞って再整理します。
1. ゼロから作らず「巨人の肩」に乗る
エンジニアの端くれとして「全部自分で書きたい」という気持ちは痛いほど分かります。しかし、競馬AI開発においては、そのプライドが挫折の元です。データの前処理や評価関数の設計など、車輪の再発明をすべきではありません。まずはGitHubで公開されている「DeepImpact」などの優れたOSS(オープンソースソフトウェア)を読み解き、それを自分の手元で動かすことから始めてください。「なぜこの特徴量を作ったのか?」「なぜこの損失関数を選んだのか?」という先駆者の思考プロセスをトレースすることが、最強の学習法です。
2. データの品質(Quality)こそが生命線
AIモデルの性能は、入力するデータの質で9割決まります(Garbage In, Garbage Out)。ネット上の無料情報をスクレイピングで集めようとするのは、労力がかかる割にリスクが高すぎるため推奨しません。サイト側の仕様変更でコードが動かなくなる「イタチごっこ」に疲弊する未来が見えています。
ここは、公式データを活用する正攻法を選びましょう。Windows専用にはなりますが、JRA公式のデータ配信サービスを活用し、pywin32ライブラリを介してデータを自動取得するパイプラインを構築することが、安定運用の第一歩です。これにより、30年分以上の正確無比な公式記録を、法的リスクなしに使い倒すことができます。
公式データの参照元
JRAシステムサービス株式会社が提供するデータサービスの詳細は、以下の公式サイトで確認できます。
(出典:JRA-VAN Data Lab. サービス概要)
3. 特徴量エンジニアリングで「AIの目」を養う
データが揃ったら、次はそれをどう料理するかです。単に「前走のタイム」や「着順」をそのまま学習させても、精度の高いモデルは生まれません。競馬は相対評価のゲームだからです。
- 相対化(Standardization):その日の馬場状態やペースに合わせて、タイムを偏差値化する。
- カテゴリ変数の数値化:Target Encodingを用いて、騎手や種牡馬を「勝率」や「期待値」という数値に変換する。
こうした一工夫を加えることで、AIは人間が見落としていた「オッズの歪み」を見抜けるようになります。ここにどれだけドメイン知識(競馬の知見)を詰め込めるかが、勝負の分かれ目です。
ちなみに、オッズの歪みについては、こちらの記事競馬のオッズの歪みとは?儲かる見つけ方と活用法を解説でも詳しく解説しています。「オッズの歪み」をもっと深く知りたい方は、ぜひチェックしてみてください。
4. 順位を当てるアルゴリズムを選定する
「1着になる確率」を計算するだけでは不十分です。競馬は「他の馬より先にゴールすること」を競う競技だからです。そのため、勾配ブースティング決定木(LightGBMやXGBoost)を使用する際は、単純な分類問題ではなく、LambdaRankなどのランキング学習(Learning to Rank)を採用しましょう。これにより、「このメンバー構成なら、この馬が上位に来る」という相対的な順序関係を学習させることができます。さらに余裕があれば、血統データをグラフ構造化(NetworkX)したり、Transformerを用いたテキスト解析を取り入れたりと、技術的な拡張性は無限大です。
5. 作って終わりではない「MLOps」の視点
モデルが完成し、一度良い結果が出たとしても、それで終わりではありません。競馬のトレンドやオッズの傾向は、生き物のように常に変化しています。先週通用したロジックが、今週も通用するとは限らないのです。
そのため、毎週末のレース結果を自動的に取り込み、バックテスト(検証)を行い、回収率をモニタリングしながらモデルを継続的にアップデートする仕組み、いわゆるMLOps(Machine Learning Operations)の視点を持つことが重要です。「予測」と「運用」、この両輪が回って初めて、安定した投資戦略が完成します。
開発のチェックリスト
- GitHubの既存コードをCloneして環境構築できたか?
- JRA-VANなどの公式データソースを確保したか?
- 時系列データを考慮した正しいバックテスト環境を作ったか?(リークの防止)
- 予測スコアをオッズと照らし合わせ、期待値(Edge)のある買い目を選定できているか?
競馬予想AIの開発は、決して平坦な道のりではありません。原因不明のエラーに悩まされたり、自信満々のモデルが全く当たらず途方に暮れる夜もあるでしょう。
しかし、自分の書いたコードが弾き出した「買い目」が、実際に万馬券を的中させた時のあの震えるような快感と達成感は、他のプログラミングプロジェクトでは決して味わえない特別なものです。それは、あなたが「不確定な未来」に対して、技術と知恵の力で勝利した何よりの証だからです。
ぜひ、あなたもPythonという頼れる相棒と共に、競馬という広大で深淵なデータの海へ漕ぎ出してみてください。その先には、きっとエンジニアとして、そして投資家としての新しい景色が待っているはずです。
-

- YUKINOSUKE
※本記事は競馬予想AIの技術的な解説を行うものであり、馬券の的中や利益を保証するものではありません。馬券の購入は自己責任で行い、無理のない範囲で競馬を楽しんでください。


コメント